


Fixa glusterfs-problem
Om du råkar ut för Peer Rejected så ska det kunna gå att fixa med följande metod.En peer kan hamnai detta tillstånd och det ses när man kör kommandot "gluster peer status". Innebörden är att synkningen kommit i olag på den volymen i klustret.
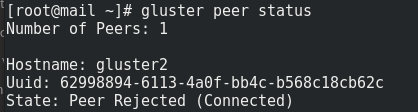
Om allt går bra är problemet snabbt återställt. Jag säger inte att det fungerar för alla, men för mig fungerade följande lösning.
Allt detta görs på den peer som är förkastad:
# systemctl stop glusterd.service
I /var/lib/glusterd, tar du bort allt utom glusterd.info (the UUID file)
# systemctl start glusterd.service
Därefter ska du upprätta kontakt med någon server som fungerar. I mitt fall var det på gluster2 jag hade problem och gjorde därför så här:
# gluster peer probe gluster1
Sen startar du om servern
# systemctl restart glusterd.service
Kolla med 'gluster peer status'
# gluster peer status
Enligt dokumentation på https://gluster.readthedocs.io/en/latest/Administrator%20Guide/Resolving%20Peer%20Rejected/ kan du behöva starta om glusterd.service någon gång medans du fortsätter att kolla tillståndet med kommandot "gluster peer status"
Gör om hela proceduren ett antal gånger om det krånglar. För mig räckte det dock att göra detta en gång. Så här ser det ut när det fungerar.
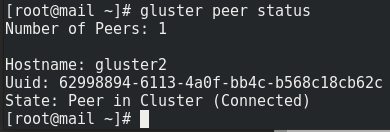
Här är hela proceduren på kommandolinjen samt resultatet. Allt är alltså gjort från den krånglande klusternoden. Skärmdumpen ovanför är från den första noden och visar den också att gluster2 (den tidigare krånglande noden) nu är okej.
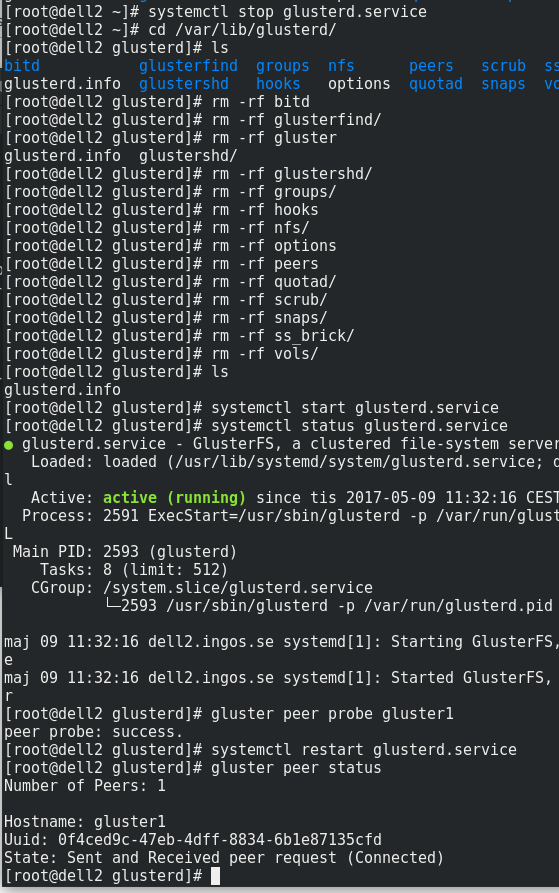
Det verkar också som att huvudservern behöver vara i gång den andra servern i klustret startas för att kontakten inte ska upphöra.